Brief summary of this article:
You can import CSV files for Portfolio Epics, Epics, Features, User Stories, Tasks, Bugs, Requests, Requesters, Users, Test Cases, Impediments in Targetprocess.
Files in CSV (Comma-separated values) format are commonly used to transfer data between spreadsheet editors (such as Microsoft Excel, OpenOffice, LibreOffice, Google Sheets) and other software systems and tools. Targetprocess supports CSV files both for Import and Export purposes.
Import from CSV files is just one method of batch data update in Targetprocess. Learn about other supported methods and choose the one that fits your needs best here: How to migrate or import data to Targetprocess from other project management system
How to prepare the CSV data file
You can create a source CSV file manually. Use any available spreadsheet editor such as Microsoft Excel, OpenOffice, LibreOffice, Google Sheets. All of them support saving data to a CSV file format.
How to perform the Import
Let’s say, we’re looking to create a simple project backlog. Stories can be added one by one, but it’d be faster to import them. For that, create a simple list with several user stories in Excel and save the file as a .csv. You can download and use this template.
Then, upload the CSV file with your data on the Settings > Import page. Customize settings and map columns.
On the first step you specify which entities you’re going to import, the entity type column (for the dynamic entity type definition), the location of your CSV file and select the column delimiter.
Delimiters
Targetprocess currently accepts 4 delimiters:
- , (comma)
- ; (semicolon)
- the Tab character
- | (the vertical bar character)
Targetprocess cannot detect the delimiter used in your file automatically. If something goes wrong and columns are not recognized please verify what delimiter is actually used in the file within plain text viewer such as Notepad tool.
Entity Type selection
In the Entity Type column, choose “UserStory” if you want to import User Stories, or e.g. “TestCase” for Test Cases.
To define the imported entities dynamically, do the Select Type to Import step. Various entity types are imported separately. After importing the entities of one type, the wizard will return you to this step again. If some entity type has been selected at Step 1, the wizard will forward you on to Step 3.
At Step 3, you should Map CSV columns.
It’s a must to map the Project and ID columns for CSV files and Targetprocess entities, mapping the other columns is optional.
If the ID property is not mapped, all the entities will be inserted as New. If the ID column is mapped but empty, the entities will also be inserted as New. If the ID column is mapped and not empty, Targetprocess will try to update IDs for the entities with values specified in the CSV file.
Import entities in a single project
The project column is not required when all the entities you import belong to the same project. You can exclude the Project column from your CSV file. Instead, select this single Project in the list of projects displayed in Step 1 of the Import wizard.
Otherwise, you have to specify the Project for your entities. The project column is required in your CSV file and should be mapped properly. You can use either numeric Project ID or text Project Name as values in the column. In this case, you may select none or two and more Projects on Step 1 of the Import wizard.
Permissions
The Team and Role access permissions remain intact for Import. Administrators can import entities to any project and team, even to the ones they are not members of.
Entities and fields mapping
List of entities and fields that can be imported from CSV files and used in columns mapping is available in the dedicated article: Entities and fields supported for import from CSV files
You can map a Targetprocess entity field with a certain CSV column, or choose the ‘Skip’ option. For example, User Story may have the “Effort” property while in the CSV file you may have the “Estimated Effort” column, and you can map them. Custom fields can be imported as well.
Usually, Targetprocess tries to define the mapping by itself, but in some cases, it may fail with the resolution.
It is not possible to map two or more columns from a CSV file to one Targetprocess entity field.
The first line of the CSV file can be skipped because usually, it contains the header and the column names, not the data itself.
When you’re done mapping columns, click Next and Targetprocess will either do the import (that’s the Perform Import step) or will display a warning for possible mapping issues so they can be fixed manually.
As the last step, you can View Log of the completed import.
Import of hierarchical backlog
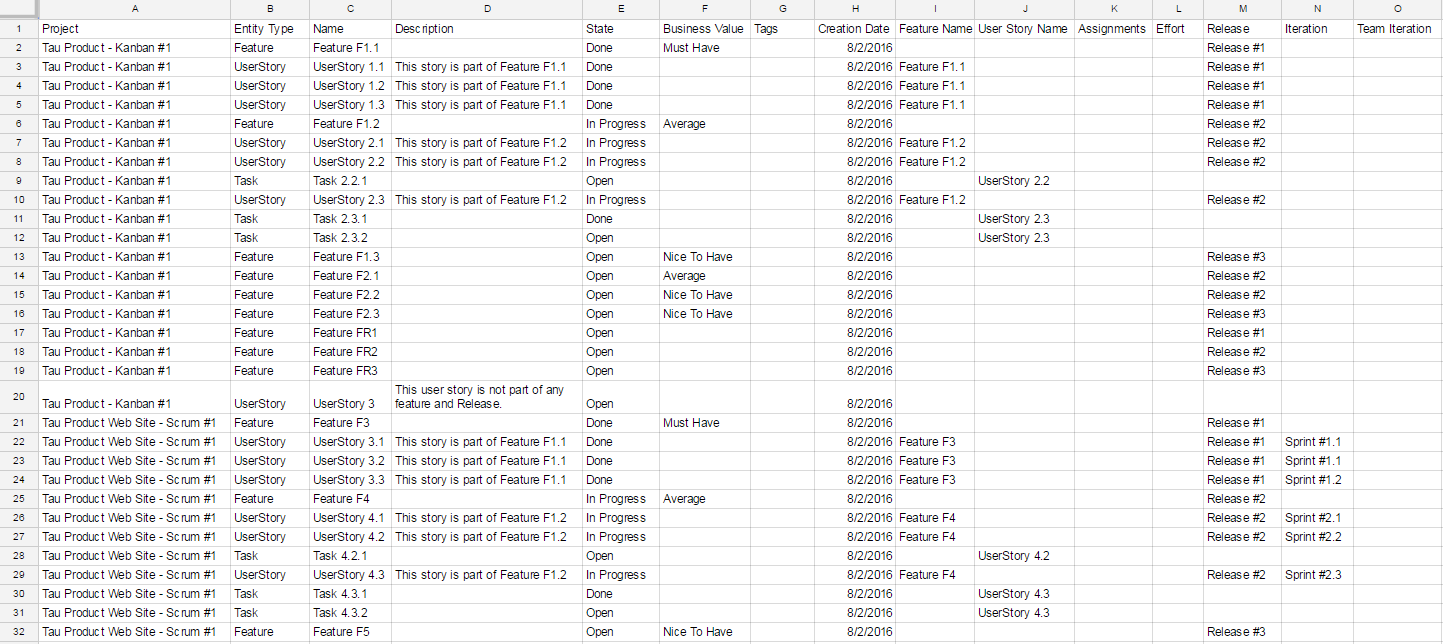
It is possible to import Features, User Stories and Tasks into your backlog altogether within a single CSV file. Find a detailed step-by-step guide in a dedicated article.
Productivity Tips
Iteratively test Import with small data snippet
When you do data import for the first time, we recommend preparing partial snippet of your data consisting of 2-5 rows, no more. Perform test import. Quite often something goes wrong and not all values are recognized properly. Delete entities imported within test attempt, fix data formatting and columns mapping issues and try once again. Import full data sheet only when all issues are resolved during tests.
Validate data after Import on a List view
When the Import is done, create a new List view and adjust filters that would show imported entities. Customize columns in the list view and try to make visible exactly the same columns that are present in your CSV file. Compare what you have in the file with what you got in the system.
Troubleshooting
Entity type must be spelled without spaces
When you have Entity Type column in your CSV file, you are able to pass through columns mapping step, but no entities are still imported, please check entity type names in the column. Names of types should not have spaces.
| Until v.3.13.4 | v3.13.5+ |
| UserStory
TestCase |
User Story
Test Case |
Also please check that all mandatory fields are mapped and filled in.
Line breaks in Descriptions
To preserve line breaks when Importing from a CSV file, please use the <br /> HTML tag.
Fields not available for mapping
When some Entity Types or Custom Fields are missing in the mapping dialogs, check the context of currently selected Projects and that your user is a member of those Projects.
Set Creation Date during import
Creation Date field in Targetprocess entities is important for history tracking. Other dates such as Start Date and End Date depend on it. These fields are used when data is displayed on roadmaps and in charts. It is not possible to modify the creation date for existing entities. It also not possible to set a start or end date to the moment before the creation date for existing entities. However, you can set custom creation dates for your new entities at the moment when you import them. More information: How to set Creation Date during import
Local symbols in names
When the CSV file contains data other than in English, it should be encoded in UTF-8 with BOM format. Find more details here.
Huge files and performance
The importing of massive files with thousands of lines is slow. It may take several hours until the import finishes. Moreover, sometimes with large files, it can stuck in the middle. Therefore, in order to increase stability and provide additional control over importing, we recommend you to split your input files into multiple batches having 500-1000 entities in each one.
See Also
Still have a question?
We're here to help! Just contact our friendly support team.
Find out more about our APIs, Automation Rules, Mashups and custom extensions.